
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- CUDA
- 공간분석
- QGIS설치
- 머신러닝
- 성능
- 1유형
- KNN
- Kaggle
- fastapi
- 2유형
- 딥러닝
- ml 웹서빙
- gradio
- webserving
- 빅데이터분석기사
- 공간시각화
- DASH
- pytorch
- dl
- streamlit
- Ai
- K최근접이웃
- ㅂ
- 캐글
- qgis
- 3유형
- GPU
- 실기
- 인공지능
- 예제소스
- Today
- Total
에코프로.AI
[AI Foundation] 딥러닝(DL) 이란? 본문


정의
딥 러닝(Deep Learning)은 머신 러닝(Machine Learning)의 특정한 한 분야로서 인공 신경망(Artificial Neural Network)의 층을 연속적으로 깊게 쌓아올려 데이터를 학습하는 방식을 말합니다. Deep 하다는 의미는 층을 연속적으로 쌓아올렸기 때문에 붙은 단어라고 보시면 쉽게 이해가 됩니다. 딥 러닝이 화두가 되기 시작한 것은 2010년대의 비교적 최근의 일이지만, 딥 러닝의 기본 구조인 인공 신경망의 역사는 생각보다 오래되었습니다. 이번 글에서는 딥 러닝의 역사부터 layer를 깊게 쌓아 학습하는 원리, 그리고 실제 산업에 적용되는 사례와 데이터/ 학습에서 주요하게 고려할 점을 다루어 보도록 하겠습니다.

Introduction to Deep Learning: What do I need to know…? | by Stacey Ronaghan
신경계에는 엄청난 수의 뉴런이 포함되어 있고, 서로 매우 복잡한 구조로 얽혀 거대한 망을 구성합니다. 이를 ‘신경망’이라고 하죠. 머신러닝 과학자들은 신경망의 구조에 착안하여 퍼셉트론을 하나의 빌딩 블록 (Building block) 이라 생각하고, 여러 개의 퍼셉트론을 연결하여 인공 신경망이라는 개념을 고안해냈습니다. 딥 러닝의 딥 (deep) 이란, 이처럼 연결된 구조로 만들어진 층(layer)에서 표현을 학습한다는 개념을 의미합니다
딥러닝의 역사
딥 러닝은 1986년 리나 데커가 소개한 머신러닝 커뮤니티에 제공되었으며, 그 이후로 인공지능의 판도를 바꾸며 새로운 수준의 능력과 이해력을 선보였습니다. 이 문단에서는 딥 러닝의 역사에 대해 소개하겠습니다.

⊙ 사전 딥 러닝 시대 (~1960년대)
1965년에 영어로 기능적인 대화를 할 수 있는 ELIZA가 공개되면서 인공지능과 인간 사이의 의사 소통에 대한 가능성이 제기되었습니다. 1967년에 개발된 ‘The nearest neighbor algorithm’은 Pattern recognition 기술의 시작이 되었습니다. 이 알고리즘은 처음에 경로 매핑에 사용되었습니다. 또한 다층 인공 뉴런 네트워크 설계의 발견으로 새로운 상황에 적응하기 위해 숨겨진 레이어를 조정할 수 있는 backpropagation 개발의 시초가 되었습니다.
⊙ 머신 러닝의 부상 (~1980년대)
1980년대에 머신러닝은 AI에 대한 새로운 접근 방식으로 등장했습니다. 머신러닝 알고리즘은 명시적으로 프로그래밍하지 않고도 데이터로부터 학습할 수 있어 전문가 시스템보다 유연하고 적응력이 뛰어납니다. 딥 러닝 알고리즘은 원시 입력에서 점진적으로 더 높은 수준의 기능을 추출하기 위해 여러 계층을 사용합니다. 이 시기는 딥 러닝의 초기였지만 backpropagation 알고리즘을 컨볼루션 신경망에 적용하면서 가능성을 확인했습니다.
⊙ 딥 러닝 혁명 (~2010년대)
2010년대에는 머신러닝의 일종인 딥러닝 알고리즘이 이미지 인식 분야에서 획기적인 발전을 이루었습니다. 이후 딥러닝은 자연어 처리, 음성 인식, 로봇 공학 등 다양한 문제에 적용되었습니다. 2017년, Ashish Vaswani와 그의 팀원들이 Transformer 모델을 도입하면서 딥 러닝의 판도가 바뀌었죠. 그들은 입력 데이터 각 부분의 중요성을 평가하기 위해 자가 주의를 사용하는 딥 러닝 모델을 보여주었습니다. 이는 NLP 작업 속도를 개선했을 뿐만 아니라, 현대에 가장 주목 받는 대형 언어 모델의 시조가 되었습니다.
⊙ 주류가 된 인공지능
우리는 산업 사례 전반에 걸쳐 AI의 접근성과 적용이 놀라울 정도로 급증하는 현재를 목격하고 있습니다. 2022년 11월 30일 ChatGPT가 출시되었으며, 2023년에는 Stable diffusion, DALL-E, Mid journey와 같은 Generative AI가 세상에 모습을 드러냈습니다. NVIDIA, Microsoft, Google, Amazon 등 AI 중점 기업은 이 물결을 적극적으로 활용하며 새로운 기술 개발에 전념하고 있습니다.
딥 러닝 모델 종류 (ANN, RNN, CNN)
딥 러닝은 방대한 양의 연산을 필요로 하기 때문에, 하드웨어가 발달하지 않았던 초기와 달리 기술이 발전한 현재에는 슈퍼컴퓨터를 기반으로 문제점을 해결할 수 있었습니다. 특히 병렬연산에 최적화된 GPU가 개발되면서 딥 러닝 기술이 본격적으로 발전하게 되었죠.
ANN 기법의 여러 문제가 해결되면서 모델 내에 은닉층을 많이 늘려 학습의 결과를 향상시키는 방법으로 등장한 DNN (Deep Neural Network)이 있습니다. 컴퓨터가 스스로 분류레이블을 만들어 내고, 공간을 왜곡하고 데이터를 구분 짓는 과정을 반복하여 최적의 구분선을 도출할 수 있습니다. 많은 데이터와 반복학습이 필요하며, 사전 학습과 오류역전파 기법을 통해 현재 널리 사용되고 있습니다. CNN, RNN, LSTM, GRU 등의 방법론이 DNN을 응용한 알고리즘입니다.
이 문단에서는 ANN, 그리고 DNN을 응용한 RNN과 CNN에 대해 설명하겠습니다.
1. ANN (Artificial Neural Network)
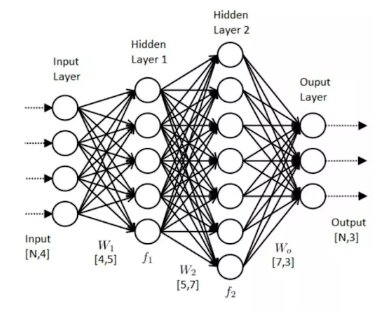
- 기존의 생물학적 신경망에서 영감을 받아 만들어진 알고리즘
- 입력과 출력 사이의 연결된 뉴런 계층으로 구성된 기본적인 인공 신경망
- 입력 데이터에서 특징을 학습하고 이를 토대로 분류 등의 작업을 수행
- 복잡한 비선형 관계를 학습할 수 있음
- 입력 데이터 간의 순서나 시간적 의존성을 고려하지 않기 때문에, 시계열 등의 데이터 처리에는 한계
2. RNN (Recurrent Neural Network)
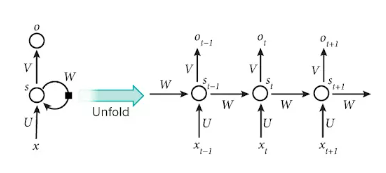
- 자신의 이전 상태를 입력으로 받고 출력으로 내보내면서 구성되는 순환 구조를 가진 신경망
- 시계열 데이터 등과 같이 같이 입력 간 순서나 시간적 의존성이 반영되어야 하는 문제에 적합
- 이전 시간 단계의 정보를 현재 시간 단계로 전달하여 과거의 정보를 활용할 수 있음
- 문장 생성, 기계 번역 등의 작업에 적용되며, 시간적인 흐름을 갖는 데이터에 적합
3. CNN (Convolution Neural Network)
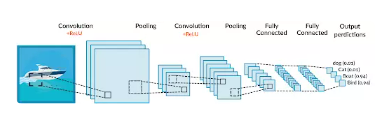
- 입력 데이터에 대해 커널 (Convolutional Kernel)을 적용하여 이미지의 특징을 추출
- 추출한 이미지의 특징은 다시 다중 신경망을 거쳐 요약 되어 출력으로 사용
- 주로 이미지 처리에 사용되는 알고리즘
- 합성곱과 풀링 등의 연산을 통해 공간적인 구조를 파악하고, 이미지의 특징을 활용하여 정확한 예측
이 중에서 CNN (Convolutional Neural Networks, ConvNet)은 현재 가장 널리 사용되는 신경망 유형입니다. CNN을 이용하면 수동으로 특징을 추출할 필요가 없어지기 때문에, 이미지를 분류하는 데 사용할 특징을 식별하지 않아도 됩니다. 자동화된 특징 추출은 Object classification (객체 분류)와 같은 컴퓨터 비전 작업에서 딥 러닝 모델을 매우 정확하게 구현한다는 장점이 있습니다.
머신러닝 vs 딥러닝
머신러닝과 딥 러닝은 인공지능의 분야에서 비슷한 개념으로 사용하지만 차이점도 분명합니다. 머신러닝은 입력 데이터와 출력 데이터 사이의 관계를 학습하는 것에 초점을 둡니다. 즉, 데이터를 분석하고 모델을 만들어 결과를 예측하는 것이 목적입니다. 따라서 수학적 모델을 사용하여 데이터를 분석하고, 데이터셋의 특징을 파악한 뒤 모델을 만들어 새로운 데이터를 예측합니다. 반면, 딥 러닝은 인공 신경망을 사용하여 입력 데이터를 처리하여 결과를 예측합니다. 딥 러닝은 머신러닝보다 더 복잡한 데이터를 처리할 수 있습니다. 이미지나 음성, 언어 등 다양한 종류의 데이터에서 더 좋은 성능을 보여주고 있습니다.
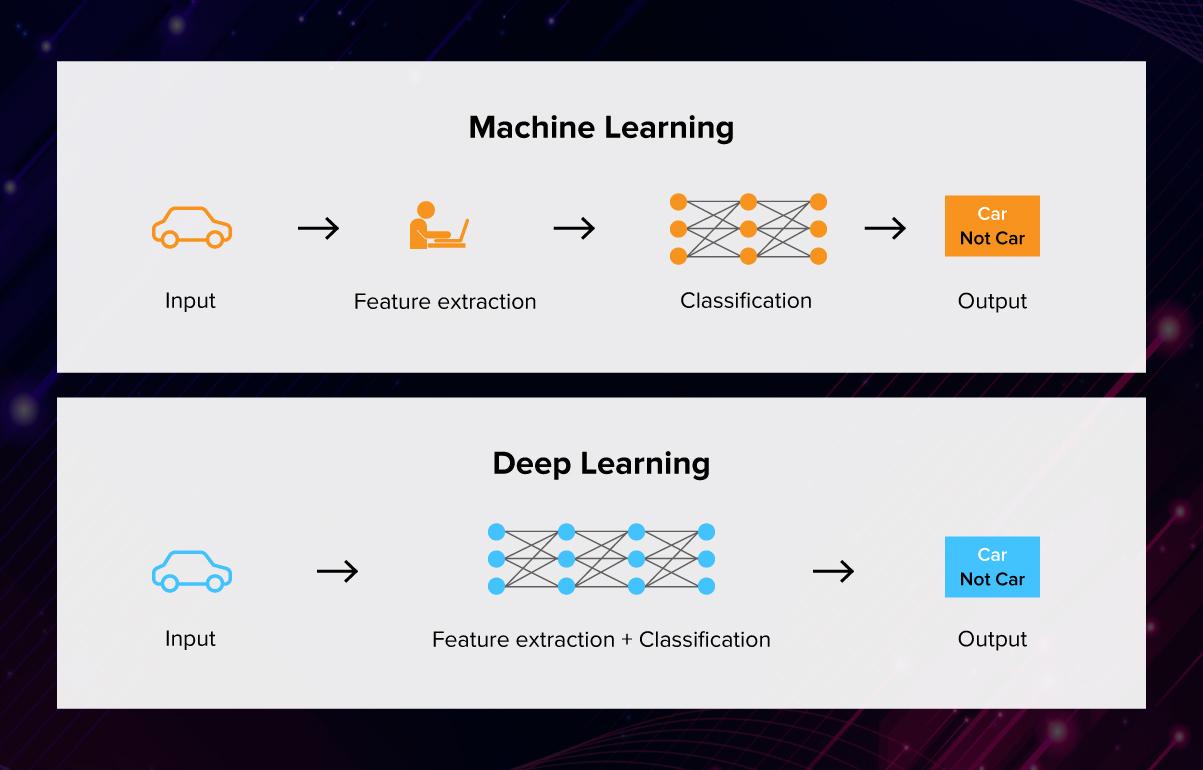
딥 러닝과 머신러닝의 차이점을 볼 수 있는 예제를 들자면 아래와 같습니다.
- 머신러닝: 이미지의 특징을 추출하고 이를 기반으로 분류 모델을 만들어 예측
이미 정해진 알고리즘으로 이미지의 특징을 추출하고 이를 토대로 Decision Tree, SVM (Support Vector Machine), Random Forest 등의 분류 알고리즘을 사용하여 분류 작업을 수행 - 딥 러닝: 인공 신경망이 학습 데이터와 정답과의 관계를 통해 이미지의 특징을 스스로 학습하고 분류 결과를 예측
입력 데이터와 출력 데이터 사이의 복잡한 관계를 스스로 학습하여 예측하기 때문에 더욱 정확한 결과를 제공
물론 그렇다고 해서 모든 분야에서 머신러닝보다 딥 러닝이 우위에 있는 것은 아닙니다. 모델이 복잡하다는 것은 학습에 필요한 데이터의 양과 학습 시간이 많이 필요하다는 뜻이기 때문이죠. 따라서 데이터가 적거나 작은 모델이 필요한 경우, 혹은 결과 해석이 필요하거나 시간과 자원의 제한이 있는 경우 딥 러닝보다 머신러닝이 유리한 선택일 수 있습니다.
[자료출처] https://www.thedatahunt.com/trend-insight/deep-learning
'AI Foundation' 카테고리의 다른 글
| [AI Foundation] 머신러닝(ML)과 수학 (0) | 2024.01.18 |
|---|---|
| [AI Foundation] 머신러닝(ML)의 6단계 워크플로우 (0) | 2024.01.18 |
| [AI Foundation] 머신러닝(ML) 개발을 위한 필요기술 (0) | 2024.01.18 |
| [AI Foundation] 머신러닝(ML)의 분류 (0) | 2024.01.18 |
| [AI Foundation] 인공지능(AI)이란? (Feat. 머신러닝(ML), 딥러닝(DL)) (0) | 2024.01.18 |



