
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 1유형
- 2유형
- 예제소스
- DASH
- dl
- gradio
- 딥러닝
- pytorch
- Ai
- 머신러닝
- qgis
- streamlit
- 인공지능
- fastapi
- 공간분석
- 실기
- K최근접이웃
- 3유형
- QGIS설치
- KNN
- 빅데이터분석기사
- GPU
- ml 웹서빙
- CUDA
- webserving
- 캐글
- 공간시각화
- ㅂ
- 성능
- Kaggle
Archives
- Today
- Total
에코프로.AI
[Python] 오토인코더(AutoEncoder) 설명 및 코드구현 (Feat. Tensorflow) 본문
AI Tutorial
[Python] 오토인코더(AutoEncoder) 설명 및 코드구현 (Feat. Tensorflow)
AI_HitchHiker 2024. 8. 28. 20:47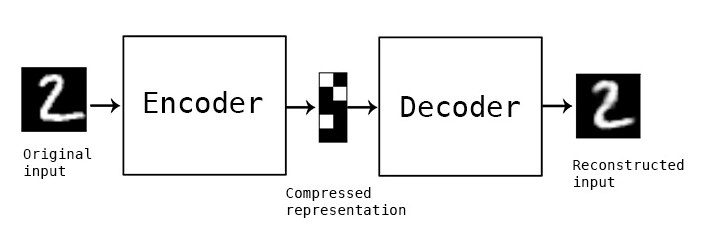
오토인코더(AutoEncoder) 란?

오토인코더는 입력데이터를 주요 특징으로 효율적으로 압축(인코딩) 한 후, 이 압축된 표현에서 원본 입력을 재구성(디코딩) 하도록 설계된 일종의 신경망 아키텍처 입니다.
- 대부분의 오토인코더 유형은 데이터압축, 이미지 노이즈 제거, 이상감지 및 안면인식 과 같은 특징 추출과 관련된 인공지능 작업에 사용됩니다.
- 변이형 오토인코더(VAE) 및 적대적 오토인코더(AAE)와 같은 특정 유형의 오토인코더는 이미지 생성 또는 시계열 데이터 생성과 같은 생성 작업에 사용할 수 있도록 오토인코더 아키텍처를 적용합니다.
- 오토인코더는 레이블이 지정된 훈련 데이터에 의존하지 않기 때문에 지도 학습 방법으로 간주되지 않습니다.
- 레이블이 지정되지 않은 데이터에서 숨겨된 패턴을 발견하도록 훈련됩니다.
- 그러나 대부분의 비지도 학습 모델과는 달리 오토인코더는 원본입력자체(또는 일부 수정된 버전)에 대한 출력을 측정할 근거가 되는 진실을 가지고 있습니다. 이러한 이유로 '자기 지도 학습', 즉 오토인코더 로 간주됩니다
오토인코더(AutoEncoder)는 어떻게 작동하나요?
오토인코더는 입력 데이터가 디코더에 도달하기 전에 '병목 지점' 을 통과시켜, 잠재적 변수를 발견합니다. 따라서 인코더는 원본 입력을 정확하게 재구성하는데 가장 도움이 되는 정보만 추출하여 전달하는 방법을 학습해야 합니다.
다양항 종류의 오토인코더가 특정 목표와 데이터 유형에 가장 적합하도록 인공 신경망의 특정 요소를 변경하지만, 모든 자동 인코더는 다음과 같은 주요 구조 요소를 공유합니다.
- 인코더는 차원감소를 통해 입력 데이터의 압축된 표현을 인코딩하는 레이어로 구성됩니다.
- 일반적으로 오토인코더에서 신경망의 숨겨된 레이어는 입력 레이어보다 점점 더 적은 수의 노드를 포함하며 데이터가 인코더 레이어를 통과할 때 작은 차원으로 '압축'되는 과정을 통해 압축됩니다.
- 병목현상 은 인코더 네트워크의 출력 레이어이자 디코더 네트워크의 입력 레이어로, 입력을 가장 압축적으로 표현한 것입니다.
- 오토인코더의 설계 및 학습의 기본 목표는 입력 데이터를 효과적으로 재구성하는데 필요한 최소한의 중요한 특징(또는 차원)을 발견하는 것입니다. 그런 다음 이 계층에서 나타나는 잠재 공간 표현, 즉 코드가 디코더에 입력 됩니다.
- 디코더 는 인코딩된 데이터 표현을 압축해제(또는 디코딩) 하여 궁극적으로 데이터를 인코딩 전의 원본 형태로 재구성하며, 점진적으로 더 많은 수의 노드가 있는 숨겨진 레이어로 구성됩니다.
- 그런 다음 이렇게 재구성된 출력을 '근거가 되는 진실(대부분의 경우 단순히 원본 입력)' 과 비교하여 오토인코더의 효율성을 측정합니다.
- 출력과 근거 진실의 차이를 재구성 오류라고 합니다.
오토인코더(AutoEncoder) 사용 사례
생성적 오토인코더와 결정론적 오코인코더 모두 서로 다른 분야와 데이터 유형에 걸쳐 다양한 사용 사례를 가지고 있습니다.
- 데이터 압축 : 오토인코더는 입력데이터의 압축된 표현을 자연스럽게 학습합니다.
- 차원감소 : 오토인코더가 학습한 인코딩은 더 큰 복합 신경망의 입력으로 사용될 수 있습니다. 복잡한 데이터의 차원 감소를 통해 다른 작업과 관련된 특징을 추출할 수 있을 뿐만 아니라 계산 속도와 효율성도 높일 수 있습니다.
- 이상감지 및 안면인식 : 오토인코더는 비교 대상인 '정상' 또는 '진짜' 예시와 비교하여 검사된 데이터의 재구성 손실을 판단함으로써 이상 징후, 사기 또는 기타 결함을 감지할 수 있으며, 반대로 실제 일치 여부를 확인할 수 있습니다.
- 이미지 노이즈제거 및 오디오 노이즈제거 : 노이즈 제거 오코인코더는 네트워크에서 학습한 잠재 공간 표현과 일치하지 않는 외부 아티팩트나 손상을 제거할 수 있습니다.
- 이미지 재구성 : 오토인코더는 노이즈 제거를 위해 학습한 반전 기술을 사용하여 이미지의 누락된 요소를 채울 수 있습니다. 이미지에 색을 입히는데로 유사하게 사용할 수 있습니다.
- 생성작업 : VAE가 학습한 것과 유사한 확률 분포를 학습하지만 KL 발산 대신 적대적 판별자 네트워크(생성적 적대 신경망 과 유사) 를 사용하는 VAE와 적대적 오토인코더(AAE)는 생성 작업에 큰 성공을 거두 었습니다.
- 오토 인코더의 대표적인 생성 어플리케이션으로는 이미지 생성을 위한 OpenAI의 오리지널 Dall-E모델과 의약품에 사용되는 분자구조 생성까지 포함됩니다.
[참고사이트] https://www.ibm.com/kr-ko/topics/autoencoder
코드구현
tensorflow.keras.datasets의 mnist 데이터를 사용해서, Encoding한후, Decoding 하여 복원하는 모델을 만들어 봅니다.
- 데이터 불러오기
from tensorflow.keras.datasets import mnist
(x_train, _), (x_test, _) = mnist.load_data()
x_train.shape, x_test.shape
- (0 ~ 1) 사이로 표준화 하기
x_train_norm = x_train / 255
x_test_norm = x_test / 255import matplotlib.pyplot as plt
plt.imshow(x_train_norm[0], cmap='Greys', vmin=0, vmax= 1)
- 모델링
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Dense, Input, Flatten, Reshape
# Encoder
encoder = Sequential()
encoder.add(Input(shape=(28, 28)))
encoder.add(Flatten()) # Output Shape : 28*28 = 784
encoder.add(Dense(256))
encoder.add(Dense(64))
encoder.add(Dense(8)) # Hidden Vector
encoder.summary()
# Decoder
decoder = Sequential()
decoder.add(Input(shape=(8, )))
decoder.add(Dense(64))
decoder.add(Dense(256))
decoder.add(Dense(28*28, activation = 'sigmoid'))
decoder.add(Reshape((28, 28)))
decoder.summary()
# AutoEncoder
# Case-1
# encoder_input = Input(shape = (28,28))
# encoder_output = encoder(encoder_input)
# decoder_output = decoder(encoder_output)
# autoencoder = Model(inputs = encoder_input, outputs = decoder_output)
# Case-2
autoencoder = Sequential([encoder, decoder])
autoencoder.summary()
autoencoder.compile(loss = 'binary_crossentropy', optimizer = 'adam')
autoencoder.fit(x_train_norm, x_train_norm, validation_data = (x_test_norm, x_test_norm), epochs = 10)

- x_test_norm 데이터 5개만 Encoding 하기
encoder.predict(x_test_norm[:5])
- 위에서 Encoding 한 값, Decoding 하기
- Decoding 하기 위해서, Encoding 된 값 numpy array로 변경
import numpy as np
code = np.array([[-4.3689375 , 0.22585988, -1.6510073 , -1.4460108 , -2.0590756 ,
-4.363275 , 0.08955172, 0.3992259 ],
[-0.63318825, 2.2652822 , -0.9761269 , -1.6669585 , 3.326361 ,
4.840438 , 1.7914327 , -0.10336711],
[-3.8271446 , -1.5858538 , -1.0632294 , 1.0515434 , 1.9012555 ,
2.031474 , 0.6574078 , -1.6086632 ],
[-1.2057486 , 4.637588 , -2.6888762 , -2.592584 , 0.63625884,
0.9025955 , -3.3599315 , 0.7690638 ],
[ 2.33869 , 1.5685922 , -0.12351003, 0.609887 , -2.7999902 ,
-0.91406596, 0.01074687, 1.3878281 ]], dtype='float32')
code
- 원본이미지, Encodig -> Decondig 한 값 비교
- 원본이미지 2, 4는 뭔가 손실이 많이 일어난거같다!
pred = encoder.predict(x_test_norm[:5])
for i in range(5):
fig, axs = plt.subplots(1,2)
axs[0].imshow(x_test_norm[i], cmap = 'Greys', vmin = 0, vmax = 1)
axs[1].imshow(decoder.predict(code)[i], cmap = 'Greys', vmin = 0, vmax = 1)



끝~

'AI Tutorial' 카테고리의 다른 글
| [텍스트마이닝] 이란? (0) | 2024.09.03 |
|---|---|
| [Python] 전이학습(Transfer Learning) 설명 (0) | 2024.08.29 |
| [Python] RNN 구현 (Feat. Tensorflow) (0) | 2024.08.28 |
| [Python] CNN 구현 (Feat. Tensorflow) (0) | 2024.08.27 |
| [머신러닝] RNN(Recurrent Neural Network) (0) | 2024.08.26 |
'AI Tutorial' Related Articles
more



