
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- Ai
- fastapi
- gradio
- 머신러닝
- pytorch
- webserving
- DASH
- 성능
- K최근접이웃
- 딥러닝
- streamlit
- GPU
- 캐글
- 공간시각화
- dl
- Kaggle
- CUDA
- 2유형
- QGIS설치
- 실기
- 공간분석
- 예제소스
- 3유형
- 1유형
- ㅂ
- qgis
- KNN
- 인공지능
- 빅데이터분석기사
- ml 웹서빙
- Today
- Total
에코프로.AI
[머신러닝] CNN(Convolutional Neural Network) 본문
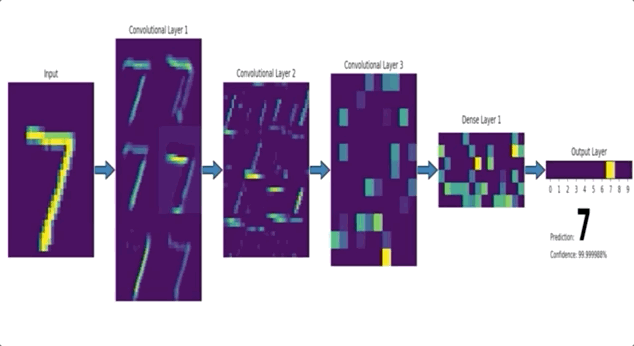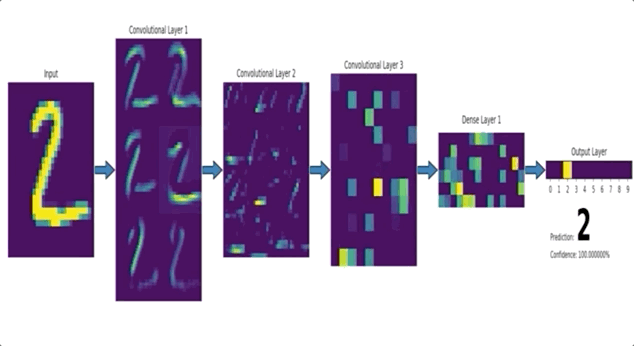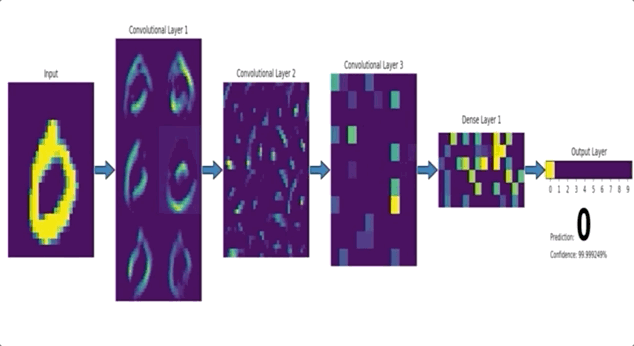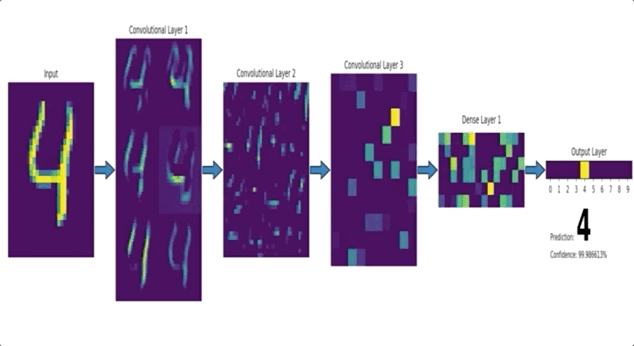
CNN 이란?
- Convolutional Neural Network, 합성곱 신경망
- 뉴럴 네트워크에서 컨볼루션 연산을 추가한 신경망입니다.
- 인간의 시신경 구조를 모방한 기술
- 이미지를 인식하기 위해 패턴을 찾는데 특히 유용함.
- 특징맵을 생성하는 필터까지도 학습이 가능해 비전(vision) 분야에서 성능이 우수함.
- 사람이 여러 데이터를 보고 기억한 후에 무엇인지 맞추는 것과 유사함.
- 데이터를 직접 학습하고 패턴을 사용해 이미지를 분류함.
- 이미지의 공간정보를 유지한 채 학습을 하게 하는 모델(1D로 변환하는 것이 아닌 2D 그대로 작업 함)
- 자율주행자동차, 얼굴인식과 같은 객체인식이나 Computer Vision 이 필요한 분야에 많이 사용되고 있음.
CNN 구조
Fully Connected Layer 만으로 구성된 인공 신경망의 입력 데이터는 1차원(배열) 형태로 한정된다. 한 장의 컬럼 사진은 3차원 데이터 이다. 배치 모드에 사용되는 여러 장의 사진은 4원 데이터이다. 사진 데이터로 전연결(FC, Fully Connected) 신경망을 학습시켜야 할 경우에, 3차원 사진 데이터를 1차원으로 평면화 시켜야 한다. 사진 데이터를 평면화 시키는 과정에서 공간 정보가 손실될 수 밖에 없다. 결과적으로 이미지 공간 정보 유실로 인한 정보 부족으로 인공 신경망이 특징을 추출 및 학습이 비효율적이고 정확도를 높이는데 한계가 있다. 이미지의 공간 정보를 유지한 상태로 학습이 가능한 모델이 바로 CNN(Convolutional Neural Network) 이다.
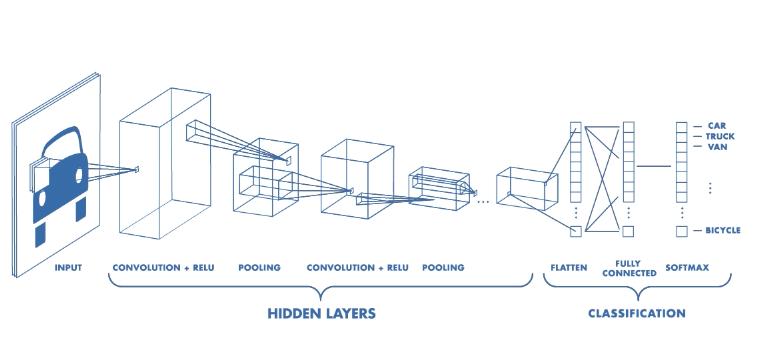
- CNN 은 위 이미지와 같이 이미지의 특징을 추출하는 부분과 클래스를 분류하는 부분으로 나눌 수 있습니다.
- 특징 추출 (Feature extraction / learning) 영역
Convolution Layer 와 Pooling Layer를 여러 겹 쌓는 형태로 구성됩니다.- Convolution Layer : 입력데이터에 필터를 적용 후, 활성화 함수를 반영하는 필수요소입니다.
- Pooling Layer : Convolution Layer 다음에 위치하며, 선택적으로 적용할 수 있습니다.
- 클래스 분류 (Classification) 영역
- CNN 마지막 부분에 위치하며, 이미지 분류(Classification)를 위한 Fully Connected Layer가 추가됩니다. 이미지의 특징을 추출하는 부분과 이미지를 분류하는 부분 사이에 이미지 형태의 데이터를 배열 형태로 만드는 Flatten 레이어가 위치합니다.
- 특징 추출 (Feature extraction / learning) 영역
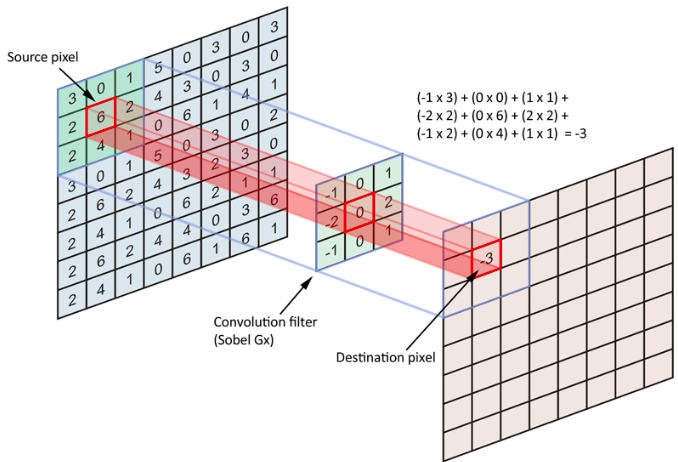
Convolution(합성곱) Layer
Convolution 이라는 용어는 두 함수를 수학적 조합하여 세 번째 함수를 생성하는 것을 말합니다. 두 세트의 정보를 병합합니다. CNN의 경우, 필터(커널)을 사용하여 입력데이터에 대한 합성곱을 수행한 다음 피쳐맵을 생성합니다.
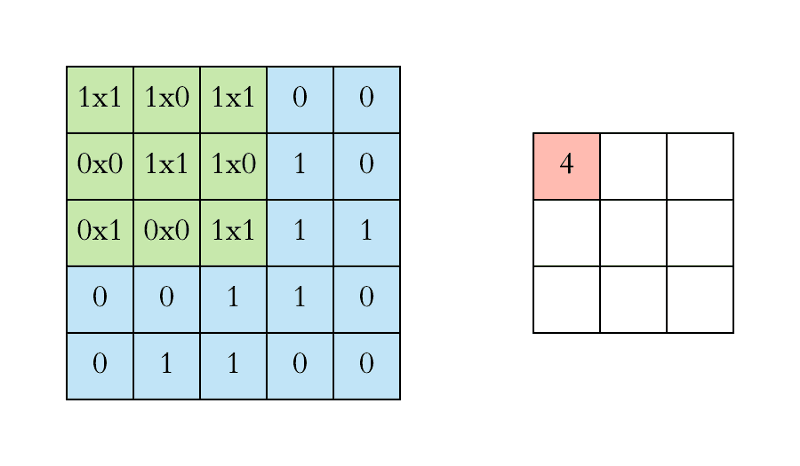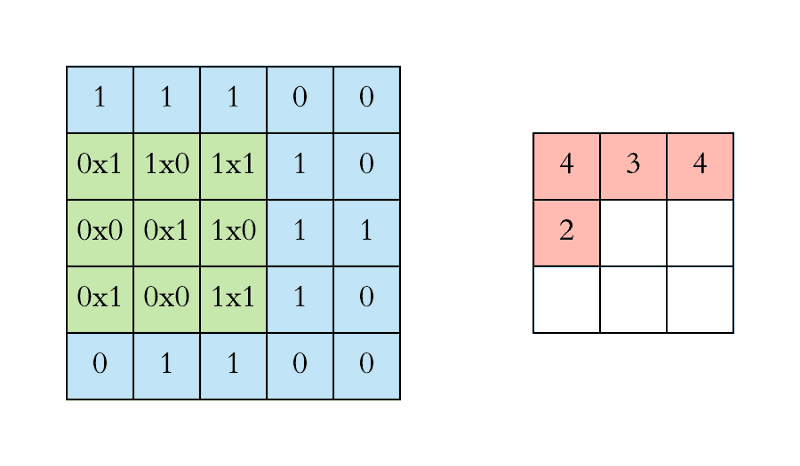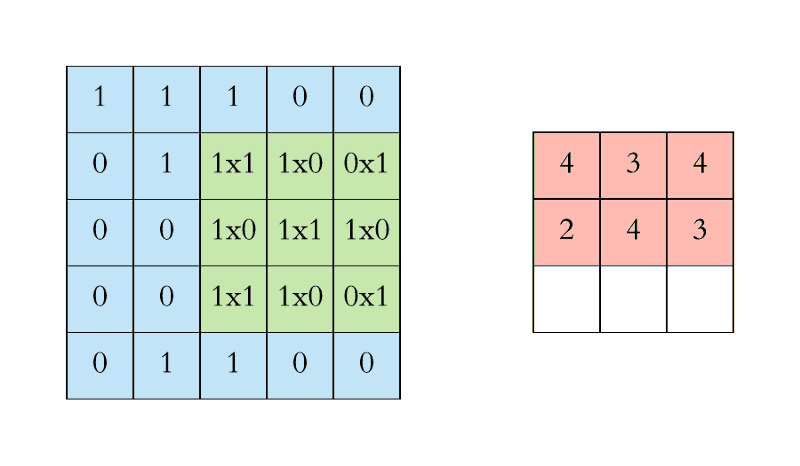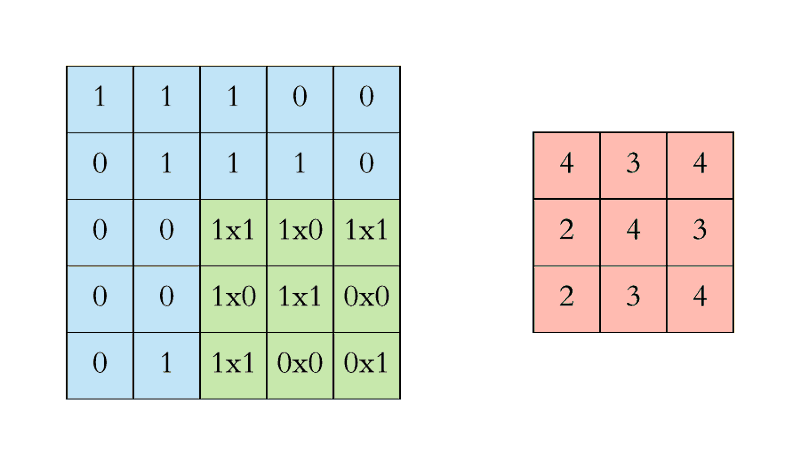
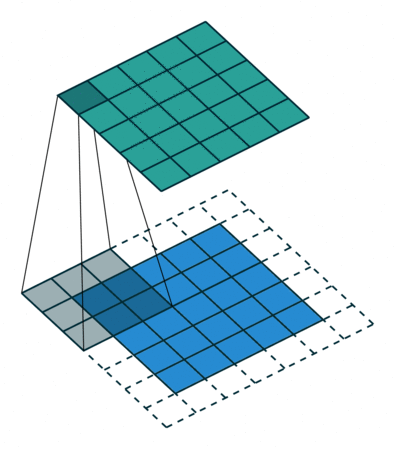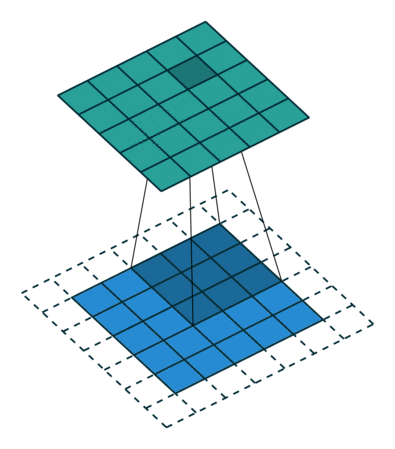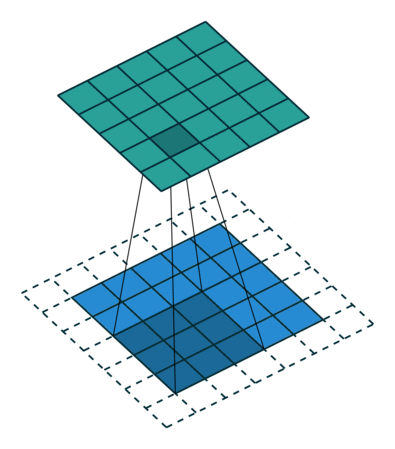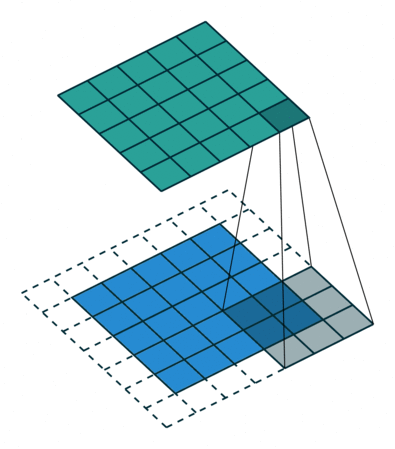
아래 애니메이션에서 Convolution 연산을 볼 수 있습니다. 필터(녹색 사각형)가 입력데이터(파란색 사각형) 를 순차적으로 Convolution 합하여 피처맵(빨간색 사각형)으로 들어가는 것을 볼 수 있습니다.
이 필터의 크기는 3x3 입니다.
실제로 작업은 3D에서 수행됩니다. 각 이미지는 너비, 높이, 깊이에 대한 차원을 가진 3D 행렬로 표현됩니다.
깊이는 이미지(RGB)에서 사용된 색상 채널로 인한 차원입니다.
- 스트라이드(Stride)
필터를 적용할 때 매번 이동하는 단계의 크기입니다. 스트라이드 크기는 일반적으로 1이며, 이는 필터가 픽셀 단위로 슬라이드한다는 것을 의미합니다. 스트라이드 크기를 늘리면 필터가 더 큰 간격으로 입력 위로 슬라이드하여 셀 간에 겹치는 부분이 줄어듭니다.
- 아래 애니메이션은 보폭 크기 1이 적용되는 모습을 보여줍니다.
- 패딩 (Padding)
입력 이미지에 대해 합성곱을 수행하면, 출력 이미지의 크기는 입력 이미지의 크기보다 작아지게 됩니다. 4x4 였던 입력 이미지가 합성곱을 수행하여 2x2의 출력 이미지의 크기를 갖습니다. 이렇게 합성곱 계층을 거치면서 이미지의 크기는 점점 작아지게 되고, 이미지의 가장자리에 위치한 픽셀들의 정보는 점점 사라지게 됩니다. 이러한 문제를 해결하기 위해 사용되는 것이 패딩(Padding) 입니다.
패딩은 아래 그림과 같이 입력 이미지의 가장자리에 특정 값으로 설절된 픽셀들을 추가함으로써 입력 이미지와 출력 이미지의 크기를 같거나 비슷하게 만드는 역할을 수행합니다. 이미지의 가장자리에 0의 값을 갖는 픽셀을 추가하는 것을 zero-padding 이라고 하며, CSS에서는 주로 zero-padding 을 사용합니다.

Pooling Layer
Pooling Layer는 합성곱 계층을 통과한 이미지의 대표적인 픽셀만 뽑는 역할을 합니다. 대표적인 Pooling 방법에는 Max Pooling, Average Pooling, Min Pooling 이 있는데, 일반적으로 CNN에서는 Max Pooling 을 많이 사용합니다. (Max Pooling 은 n x n 픽셀에서 가장 큰 값만 추출합니다)
Pooling의 특징은 다음과 같습니다.
- 이미지의 데이터의 크기가 줄어 CNN에서 계산량을 줄일 수 있습니다.
- 노이즈를 줄일 수 있습니다.
- 이미지의 국소적인 영역에서는 픽셀의 위치가 바뀌어도 Pooling 결과는 동일하기 때문에 이미지를 구성하는 요소가 바뀌어도 CNN의 출력값이 영향을 받지 않는다.

Fully Connected Layer
이미지 특징을 추출하여, 이것이 무엇을 의미하는 데이터 인지를 분류하는 작업입니다. 앞에서 모든 처리를 거친 이미지 데이터를 1D Array로 변환하여(Flatten), Softmax 함수를 적용할 수 있게끔 변환합니다.
- Flatten Layer : 데이터 타입을 Fully Connected 네트워크 형태로 변경, 입력데이터의 shape 변경만 수행
- Softmax Layer : Classification 수행
'AI Tutorial' 카테고리의 다른 글
| [Python] CNN 구현 (Feat. Tensorflow) (0) | 2024.08.27 |
|---|---|
| [머신러닝] RNN(Recurrent Neural Network) (0) | 2024.08.26 |
| [Python] 크롤링 (Feat. 구글 이미지 저장) (0) | 2024.08.23 |
| [Tensorflow] mnist 데이터셋 손글씨 예측 모델링(Feat. DNN 모델) (0) | 2024.08.22 |
| [Tensorflow] Tensorflow 소개 및 간단한 모델링 (0) | 2024.08.22 |



