
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 딥러닝
- ml 웹서빙
- qgis
- DASH
- 공간시각화
- streamlit
- ㅂ
- 실기
- gradio
- GPU
- 1유형
- CUDA
- fastapi
- KNN
- 예제소스
- 2유형
- 성능
- dl
- 공간분석
- 캐글
- Kaggle
- Ai
- QGIS설치
- 인공지능
- 머신러닝
- 3유형
- K최근접이웃
- 빅데이터분석기사
- pytorch
- webserving
- Today
- Total
에코프로.AI
[Hugging Face - 1] Hugging Face 소개 및 기본사용(Feat. pipeline) 본문
[Hugging Face - 1] Hugging Face 소개 및 기본사용(Feat. pipeline)
AI_HitchHiker 2024. 12. 23. 15:11
1. Hugging Face란 무엇인가?
Hugging Face는 자연어 처리(NLP)와 머신러닝(ML) 모델의 개발 및 배포를 돕는 오픈소스 중심의 AI 플랫폼입니다. 특히 Transformers 라이브러리를 통해 딥러닝 기반의 NLP 모델(예: BERT, GPT, T5 등)을 손쉽게 사용할 수 있도록 지원합니다. 최근에는 컴퓨터 비전(CV)과 멀티모달 모델로도 확장되고 있으며, 모델 허브, 데이터셋, 교육 자료를 제공해 AI 개발자와 연구자에게 필수적인 도구로 자리 잡고 있습니다.
2. 인공지능 개발에 유용한 이유
- 오픈소스 접근성 : 최신 AI 모델을 무료로 활용하고 수정할 수 있는 강력한 오픈소스 라이브러리를 제공합니다.
- 사전 훈련된 모델 : 수천 개의 사전 훈련된 모델을 통해 개발자가 시간과 비용을 절감할 수 있습니다.
- 다양한 지원 언어 : 다양한 프로그래밍 언어와 플랫폼에 걸쳐 사용 가능하며, Python 기반의 통합이 특히 용이합니다.
- 사용자 친화성 : 직관적인 API와 문서를 통해 초보자도 쉽게 접근 가능하며, 개발 속도를 높이는 데 기여합니다.
- 커뮤니티 : 활발한 커뮤니티와 데이터셋 및 학습 자료를 공유할 수 있는 플랫폼을 제공합니다.
3. Hugging Face의 주요 기능
- Transformers 라이브러리 : NLP, CV, 음성 처리 등 다양한 AI 모델을 지원.
- Datasets 라이브러리 : 손쉽게 데이터셋을 검색, 로드, 전처리할 수 있는 도구.
- Tokenizers 라이브러리 : 다양한 언어에 맞춘 고성능 토크나이저 제공.
- Model Hub : 연구자 및 개발자가 공유하는 100,000개 이상의 모델 저장소.
- Inference API : 모델을 별도 서버 없이 Hugging Face 클라우드에서 실행.
- Spaces : Streamlit, Gradio 등으로 사용자 정의 AI 애플리케이션을 구축할 수 있는 호스팅 플랫폼.
4. Transformers를 사용하는 간단한 예시 (feat. pipeline)
다음은 Hugging Face의 Transformers 라이브러리를 이용한 예시입니다.
Transformers와 PyTorch를 다음과 같이 설치합니다.
!pip install 'transformers[torch]'sentiment-analysis (감정분석)
사전 훈련된 BERT 모델을 사용하여 감정 분석을 수행하는 간단한 예시 코드 입니다.
from transformers import pipeline
# 사전 훈련된 sentiment-analysis 모델 로드
classifier = pipeline("sentiment-analysis")
# 테스트 데이터
text = ["I love Hugging Face!", "This is a bit disappointing."]
# 감정 분석 실행
results = classifier(text)
# 결과 출력
for idx, result in enumerate(results):
print(f"Text: {text[idx]}")
print(f"Label: {result['label']}, Score: {result['score']:.4f}")
실행 결과 예시
ext: I love Hugging Face!
Label: POSITIVE, Score: 0.9999
Text: This is a bit disappointing.
Label: NEGATIVE, Score: 0.9998
zero-shot-classification (제로샷분류)
사전 훈련된 BART 모델을 사용하여 제로샷분류를 수행하는 간단한 예시 코드 입니다.
from transformers import pipeline
classifier = pipeline("zero-shot-classification")
classifier(
"This is a course about the Transformers library",
candidate_labels=["education", "politics", "business"],
)
실행 결과 예시
{'sequence': 'This is a course about the Transformers library',
'labels': ['education', 'business', 'politics'],
'scores': [0.8445994257926941, 0.11197380721569061, 0.04342673346400261]}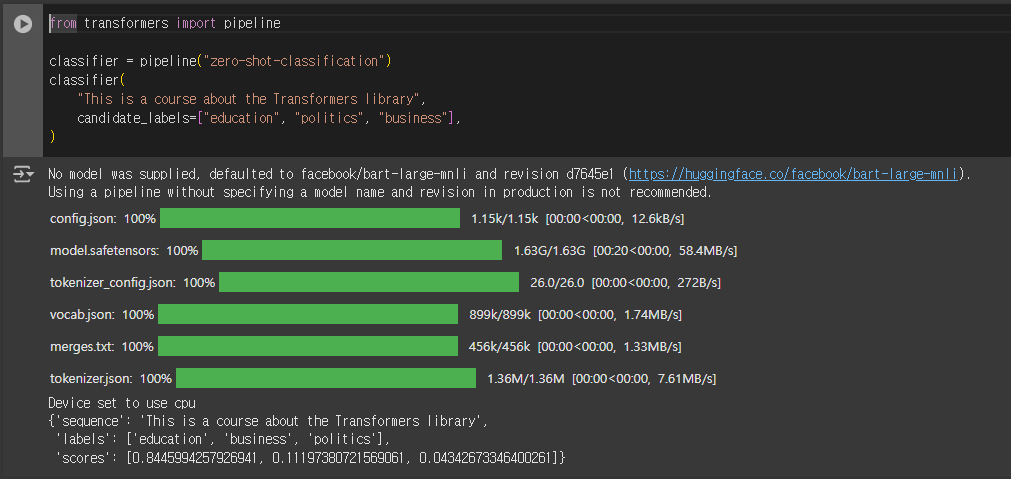
text-generation (텍스트 생성)
사전 훈련된 gpt2 모델을 사용하여 텍스트생성을 수행하는 간단한 예시 코드 입니다.
- 여기서 중요한 아이디어는 프롬프트를 제공하면 모델이 나머지 텍스트를 생성하여 자동으로 완성한다는 것입니다
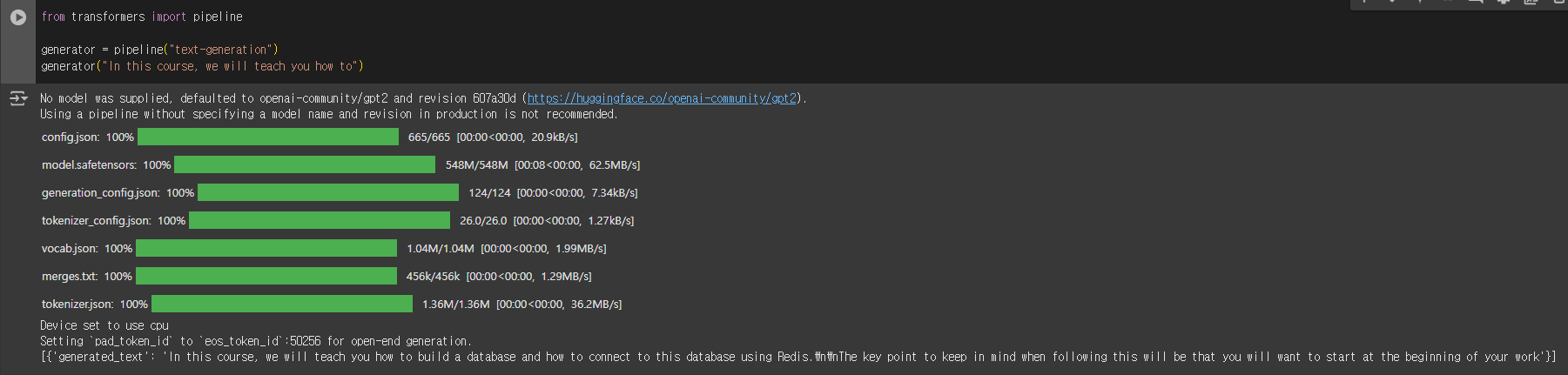
from transformers import pipeline
generator = pipeline("text-generation")
generator("In this course, we will teach you how to")
실행 결과 예시
[{'generated_text': 'In this course, we will teach you how to build a database and how to connect to this database using Redis.\n\nThe key point to keep in mind when following this will be that you will want to start at the beginning of your work'}]
사전 훈련된 distilgpt2 모델을 사용하여 텍스트생성을 수행하는 간단한 예시 코드 입니다.
from transformers import pipeline
generator = pipeline("text-generation", model="distilgpt2")
generator(
"In this course, we will teach you how to",
max_length=30,
num_return_sequences=2,
)
실행 결과 예시
[{'generated_text': "In this course, we will teach you how to do this in a few minutes. I'd love to hear if you enjoyed it. As soon as"},
{'generated_text': 'In this course, we will teach you how to solve the issue and present it that way.\u200d'}]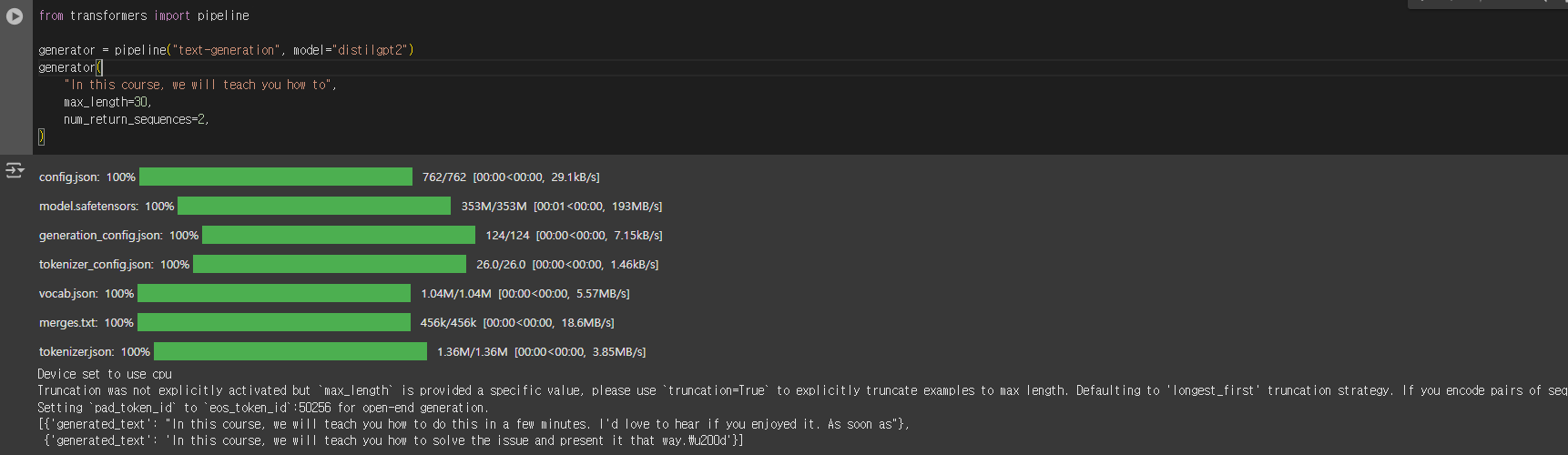
fill-mask (마스크 채우기)
사전 훈련된 distilbert 모델을 사용하여 마스크채우기 를 수행하는 간단한 예시 코드 입니다.
- 이 작업의 아이디어는 주어진 텍스트의 빈칸을 채우는 것입니다.
- 인수 top_k는 표시하려는 가능성의 수를 제어합니다. 여기서 모델은 종종 마스크 토큰<mask> 이라고 하는 특수 단어를 채웁니다 . 다른 마스크 채우기 모델은 다른 마스크 토큰을 가질 수 있으므로 다른 모델을 탐색할 때 항상 적절한 마스크 단어를 확인하는 것이 좋습니다. 이를 확인하는 한 가지 방법은 위젯에서 사용된 마스크 단어를 보는 것입니다.
from transformers import pipeline
unmasker = pipeline("fill-mask")
unmasker("This course will teach you all about <mask> models.", top_k=2)
실행 결과 예시
[{'score': 0.19198468327522278,
'token': 30412,
'token_str': ' mathematical',
'sequence': 'This course will teach you all about mathematical models.'},
{'score': 0.042092032730579376,
'token': 38163,
'token_str': ' computational',
'sequence': 'This course will teach you all about computational models.'}]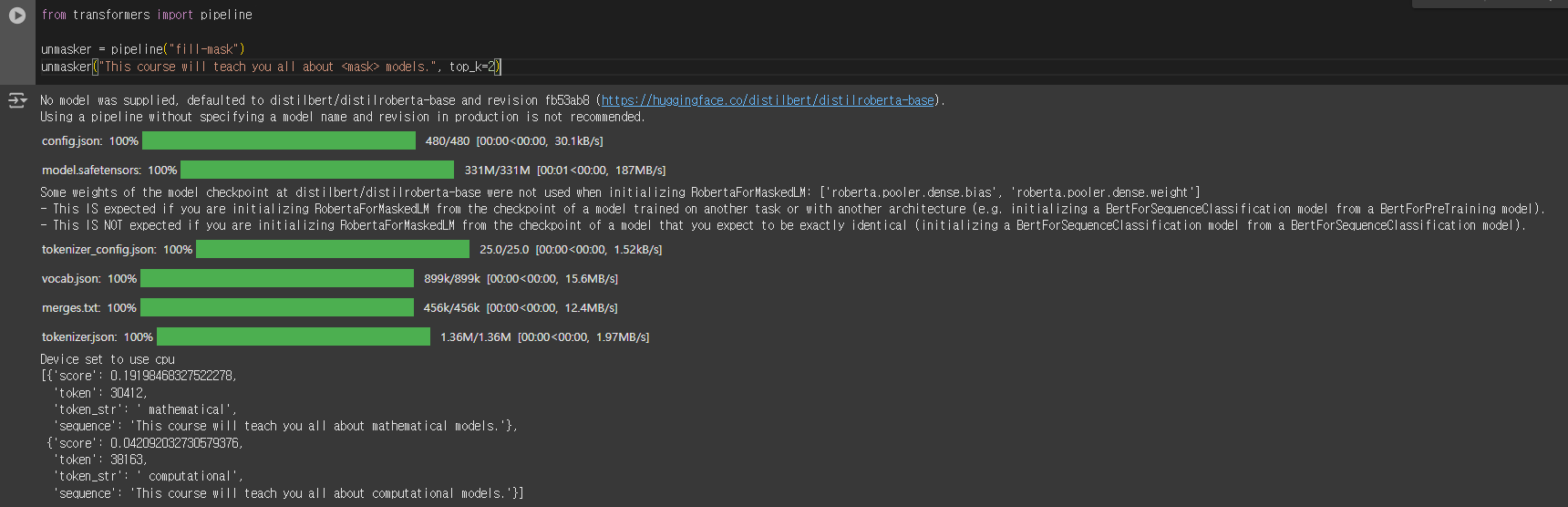
ner (명명된 엔터티 인식)
사전 훈련된 bert 모델을 사용하여 명명된 엔터티 인식을 수행하는 간단한 예시 코드 입니다.
- 델이 입력 텍스트의 어느 부분이 사람, 위치 또는 조직과 같은 엔터티에 해당하는지 찾아야 하는 작업입니다
from transformers import pipeline
ner = pipeline("ner", grouped_entities=True)
ner("My name is Sylvain and I work at Hugging Face in Brooklyn.")
실행 결과 예시
여기에서 모델은 Sylvain이 사람(PER), Hugging Face가 조직(ORG), Brooklyn이 위치(LOC)라는 것을 올바르게 식별했습니다.
[{'entity_group': 'PER',
'score': 0.9981694,
'word': 'Sylvain',
'start': 11,
'end': 18},
{'entity_group': 'ORG',
'score': 0.9796019,
'word': 'Hugging Face',
'start': 33,
'end': 45},
{'entity_group': 'LOC',
'score': 0.9932106,
'word': 'Brooklyn',
'start': 49,
'end': 57}]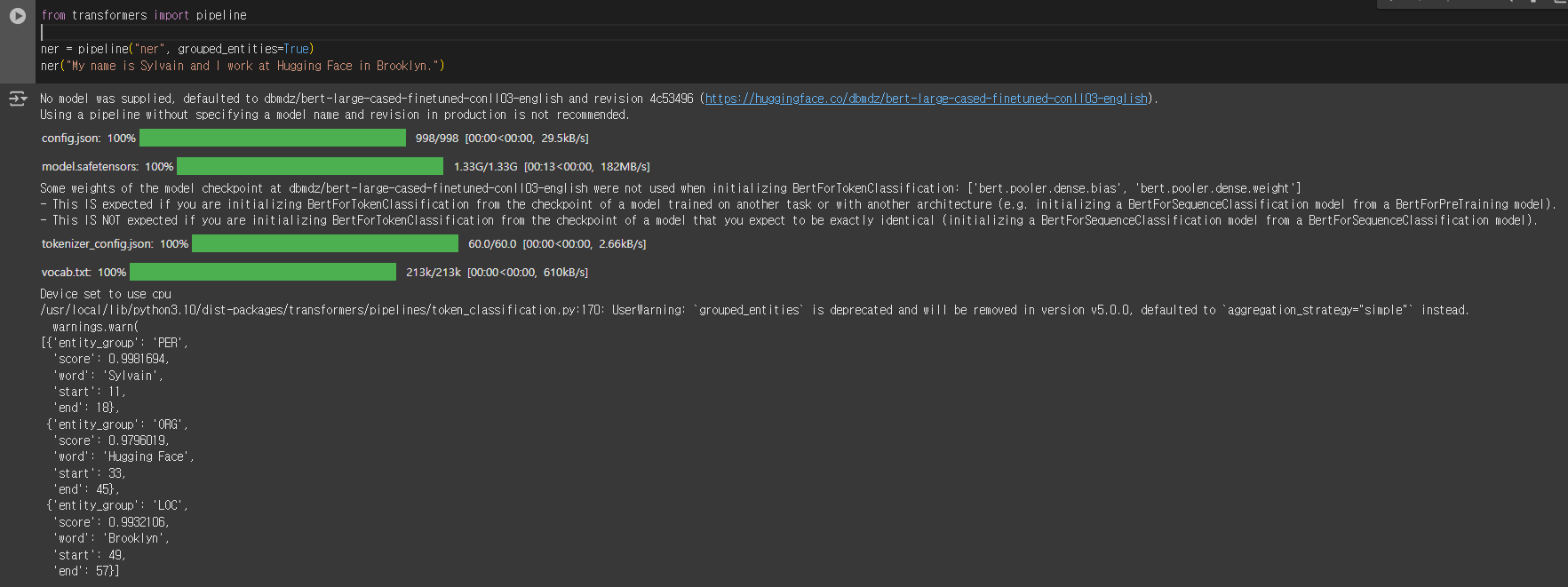
question-answering (질문 답변)
사전 훈련된 distilbert 모델을 사용하여 질문 답변을 수행하는 간단한 예시 코드 입니다.
- 주어진 맥락의 정보를 사용하여 질문에 답합니다
from transformers import pipeline
question_answerer = pipeline("question-answering")
question_answerer(
question="Where do I work?",
context="My name is Sylvain and I work at Hugging Face in Brooklyn",
)
실행 결과 예시
{'score': 0.6949766278266907, 'start': 33, 'end': 45, 'answer': 'Hugging Face'}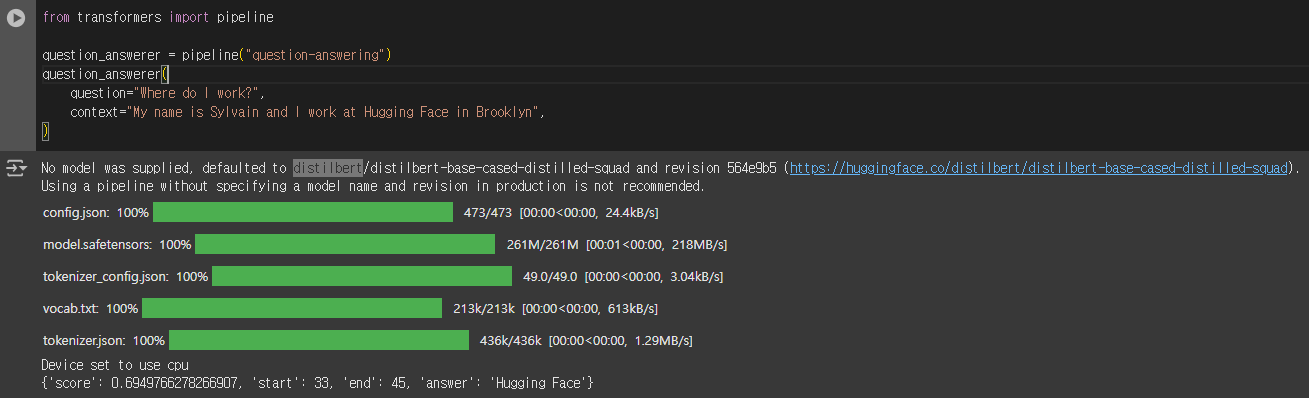
summarization (요약)
사전 훈련된 distilbart 모델을 사용하여 요약을 수행하는 간단한 예시 코드 입니다.
- 요약은 텍스트에서 참조된 모든(또는 대부분의) 중요한 측면을 유지하면서 텍스트를 더 짧은 텍스트로 줄이는 작업입니다.
from transformers import pipeline
summarizer = pipeline("summarization")
summarizer(
"""
America has changed dramatically during recent years. Not only has the number of
graduates in traditional engineering disciplines such as mechanical, civil,
electrical, chemical, and aeronautical engineering declined, but in most of
the premier American universities engineering curricula now concentrate on
and encourage largely the study of engineering science. As a result, there
are declining offerings in engineering subjects dealing with infrastructure,
the environment, and related issues, and greater concentration on high
technology subjects, largely supporting increasingly complex scientific
developments. While the latter is important, it should not be at the expense
of more traditional engineering.
Rapidly developing economies such as China and India, as well as other
industrial countries in Europe and Asia, continue to encourage and advance
the teaching of engineering. Both China and India, respectively, graduate
six and eight times as many traditional engineers as does the United States.
Other industrial countries at minimum maintain their output, while America
suffers an increasingly serious decline in the number of engineering graduates
and a lack of well-educated engineers.
"""
)
실행 결과 예시
[{'summary_text': ' America has changed dramatically during recent years . The number of engineering graduates in the U.S. has declined in traditional engineering disciplines such as mechanical, civil, electrical, chemical, and aeronautical engineering . Rapidly developing economies such as China and India continue to encourage and advance the teaching of engineering .'}]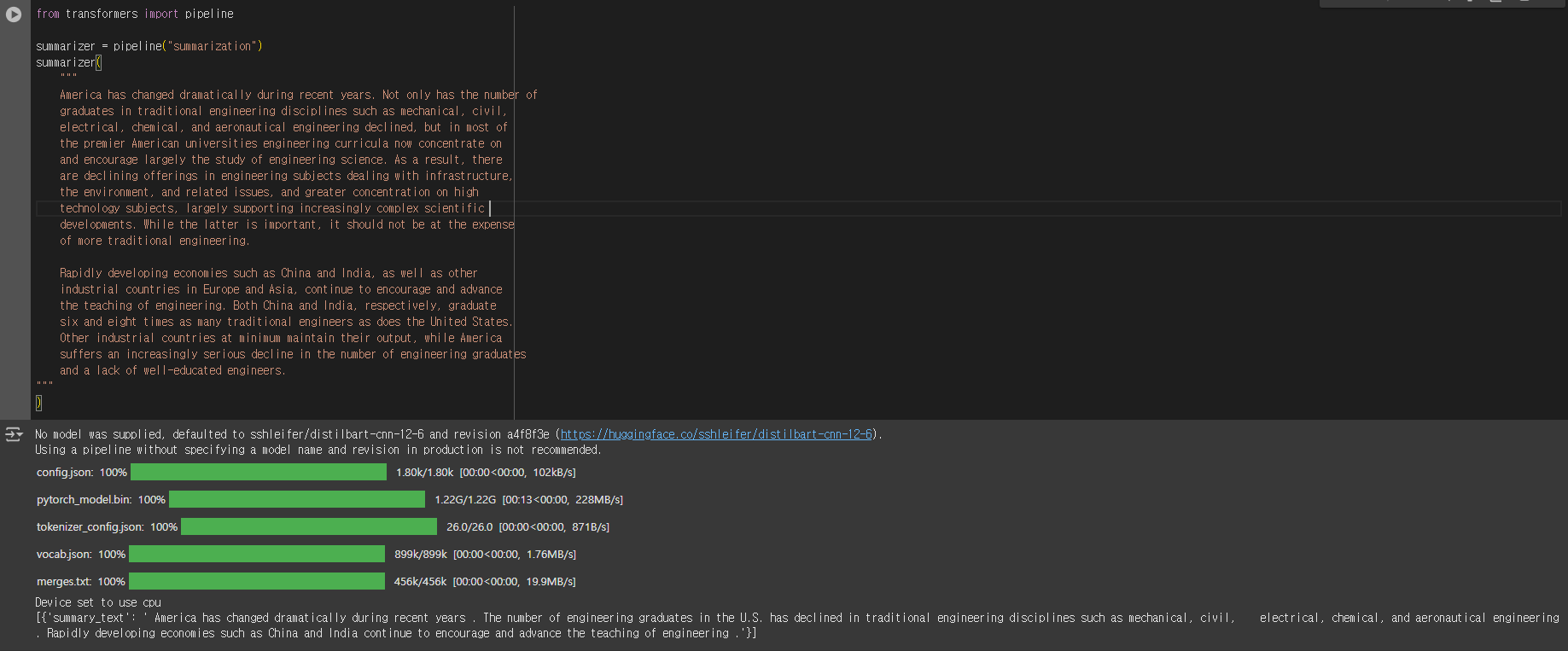
translation (번역)
사전 훈련된 Helsinki-NLP/opus-mt-fr-en 모델을 사용하여 프랑스어를 영어로 번역을 수행하는 간단한 예시 코드 입니다.
from transformers import pipeline
translator = pipeline("translation", model="Helsinki-NLP/opus-mt-fr-en")
translator("Ce cours est produit par Hugging Face.")
실행 결과 예시
[{'translation_text': 'This course is produced by Hugging Face.'}]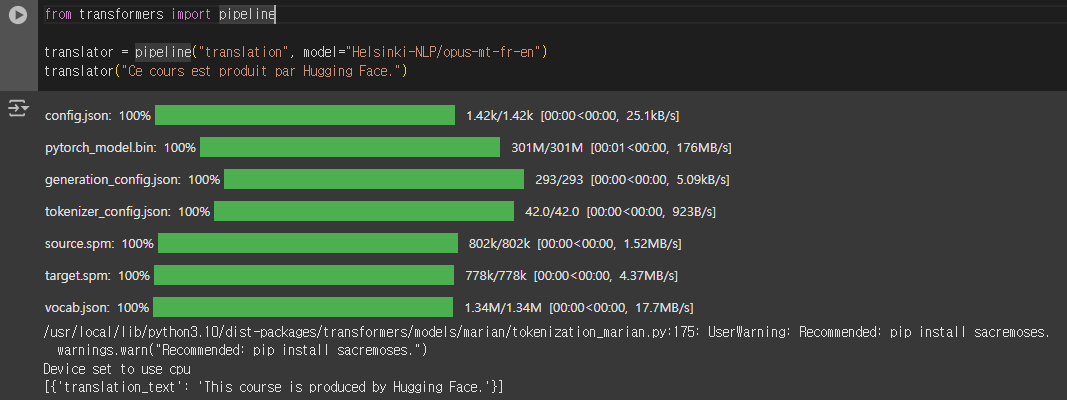
[참고사이트] https://huggingface.co/learn/nlp-course/chapter1/3?fw=pt
끝~

'AI Tutorial' 카테고리의 다른 글
| [Hugging Face - 3] pipeline() 함수 - 내부 처리로직 (2) | 2024.12.27 |
|---|---|
| [Hugging Face - 2] Transformer? (1) | 2024.12.24 |
| [Streamlit] PostgreSQL 연동 (0) | 2024.12.23 |
| [Python 모델 서빙] DJango - 써보기(Visual Studio Code에서 Django 튜토리얼-1) (0) | 2024.12.19 |
| [Python 모델 서빙] Flask - 써보기(Visual Studio Code의 Flask 튜토리얼 - 1) (0) | 2024.12.16 |



