
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 인공지능
- 성능
- 딥러닝
- fastapi
- 캐글
- dl
- webserving
- pytorch
- CUDA
- gradio
- 공간시각화
- ㅂ
- Ai
- 머신러닝
- Kaggle
- GPU
- QGIS설치
- ml 웹서빙
- 예제소스
- K최근접이웃
- streamlit
- 2유형
- 1유형
- 공간분석
- 실기
- 3유형
- DASH
- 빅데이터분석기사
- qgis
- KNN
- Today
- Total
에코프로.AI
[Streamlit] PostgreSQL 연동 본문

1. 아래의 링크를 확인하여, PostgreSQL 과 dbeaver 를 설치 해 줍니다.
PostgreSQL 설치 및 데이터 저장 (Feat. Python)
PostgreSQL & DBeaver 설치PostgreSQL 다운로드 및 설치PostgreSQL 사이트https://www.postgresql.org/download/windows/PostgreSQL 다운로드 사이트https://www.enterprisedb.com/downloads/postgres-postgresql-downloads아래와 같은 화면에서
www.ecopro.ai
1.1. Dbeaver 를 실행해 줍니다.
1.2. PostgreSQL 연결
1.2.1. 좌측 위의 새 데이터베이스 연결(콘센트+ 모양)의 아이콘을 클릭합니다.
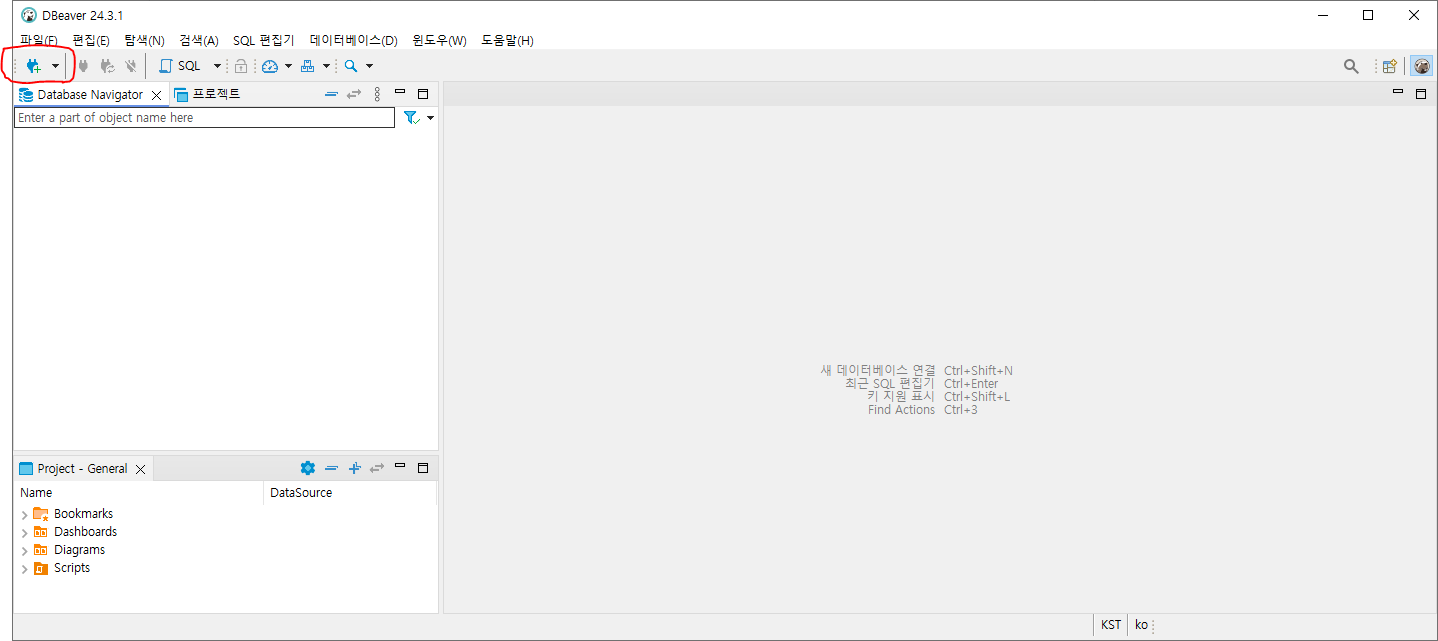
1.2.2. 여러가지 DB를 선택해서 접속할 수 있습니다. 이 중에서 "PostgreSQL"을 선택 후, "다음(N)"을 선택합니다.

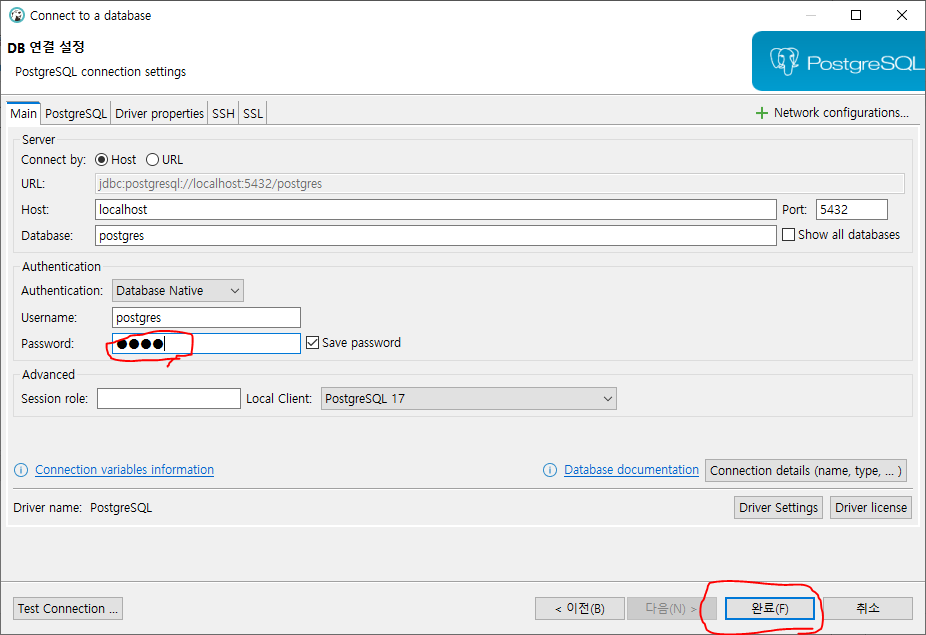
1.2.3. PostgreSQL을 설치할 때, 설정한 Password를 입력 후, "완료(F)"를 선택합니다.
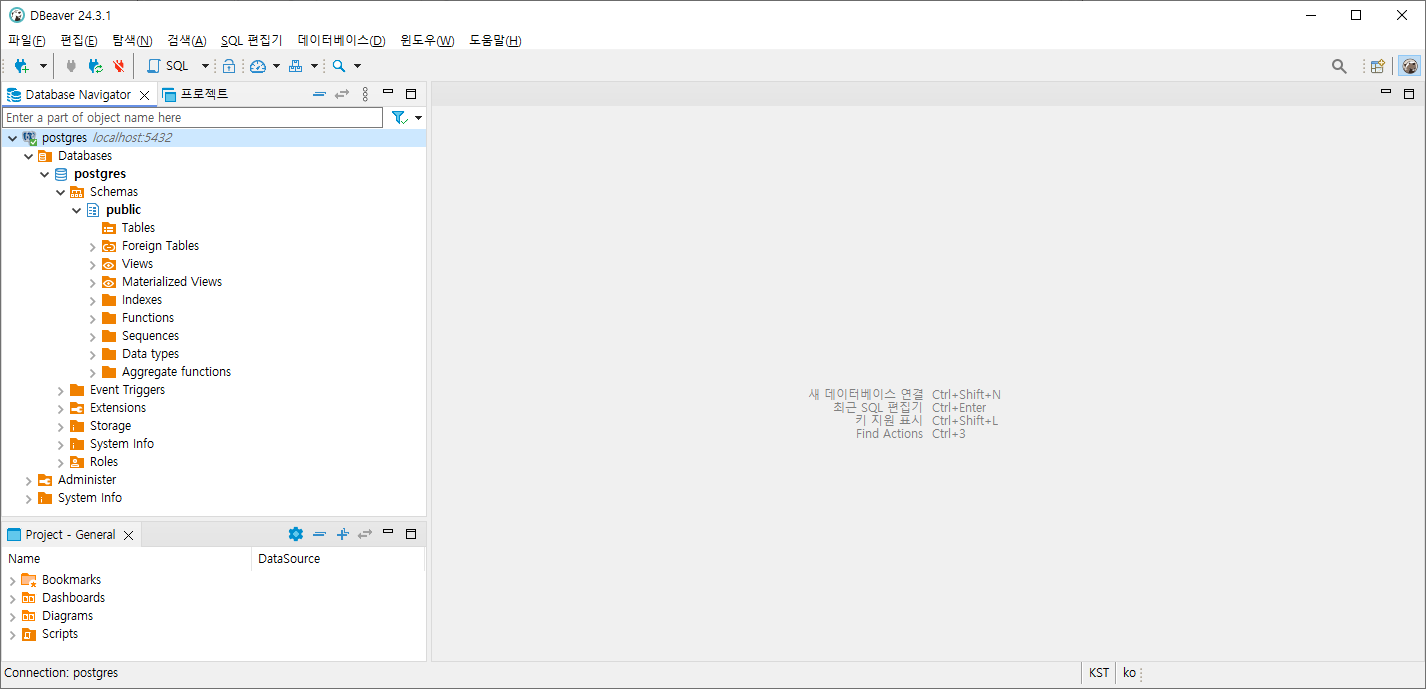
1.2.4. 아래와 같이 posgres DB가 연결된 것을 확인할 수 있습니다.
1.3. reports 테이블 생성 및 데이터입력
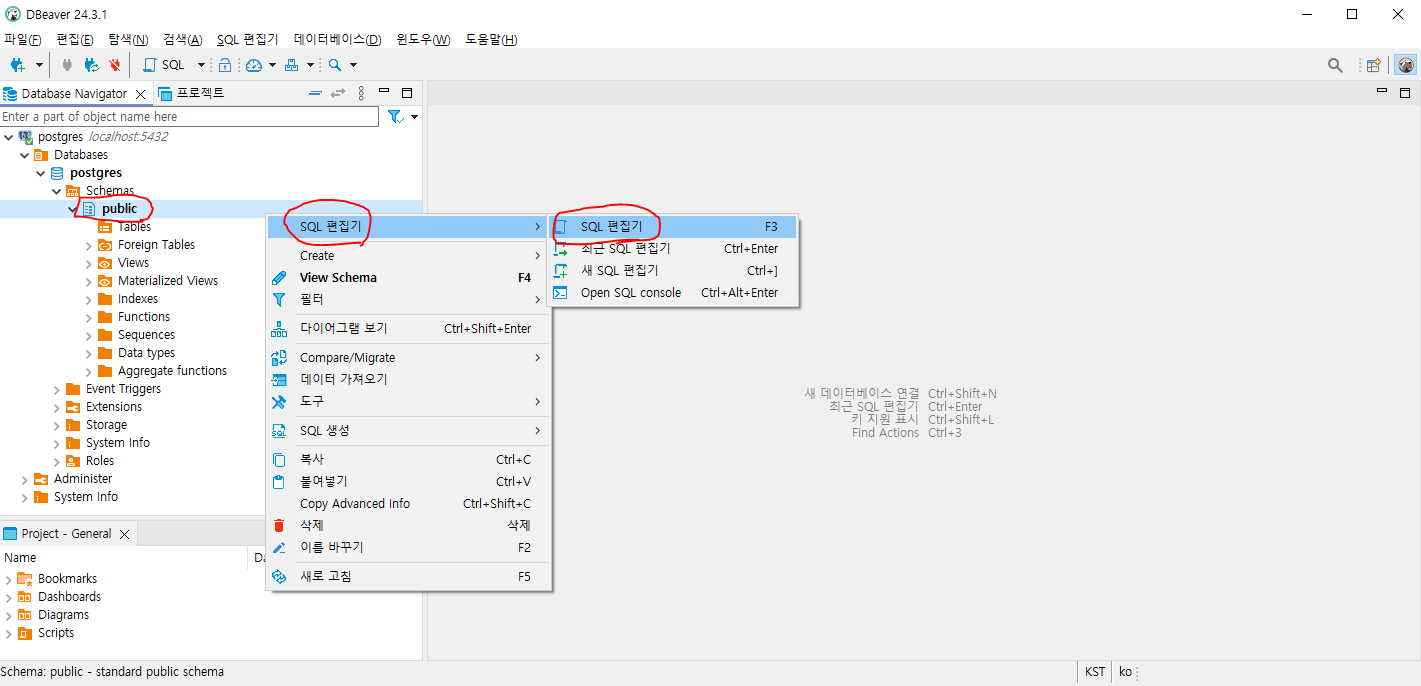
1.3.1. 아래 그림과 같이 Schemes의 public에서 마우스 오른쪽 클릭 후, "SQL 편집기" -> "SQL 편집기" 선택
1.3.2. 실행 된 SQL 편집기에 아래의 쿼리문 입력 후, 실행
# 테이블 생성
CREATE TABLE reports (
id SERIAL PRIMARY KEY,
report_date DATE NOT NULL,
category VARCHAR(50),
sales_amount NUMERIC
);
# 데이터 입력
INSERT INTO reports (report_date, category, sales_amount)
VALUES
('2023-12-01', 'Electronics', 1000),
('2023-12-01', 'Clothing', 500),
('2023-12-02', 'Electronics', 1500),
('2023-12-02', 'Clothing', 700);
- 실행은 아래와 같이 테이블생성, 데이터입력을 나눠서 실행해 줍니다. 마우스로 선택 된 부분만 실행을 합니다.
실행은 아래의 쿼리의 좌측의 노란색 화살표를 선택하거나, (Ctrl + Enter) 를 입력합니다.
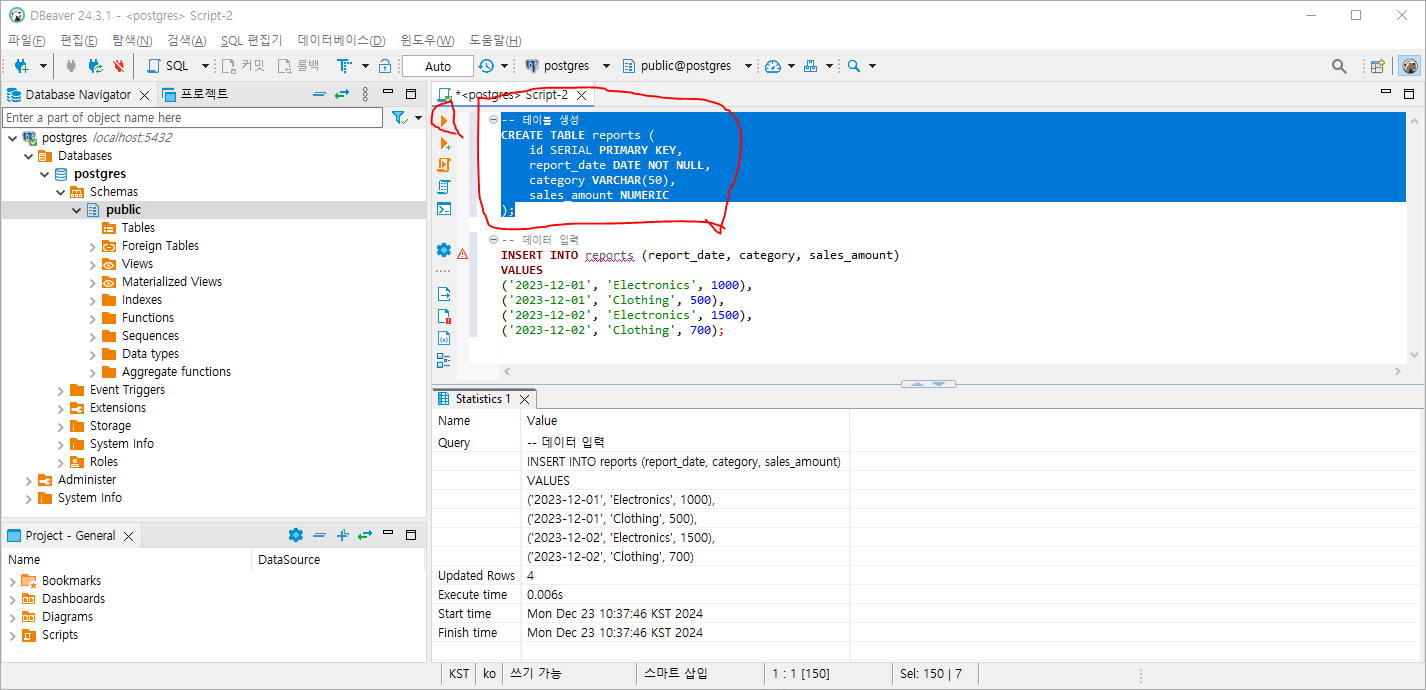
테이블생성 (아래와 같이 마우스로 쿼리 선택 후, 쿼리의 좌측의 노란색 화살표를 선택하거나, (Ctrl + Enter) 를 입력)
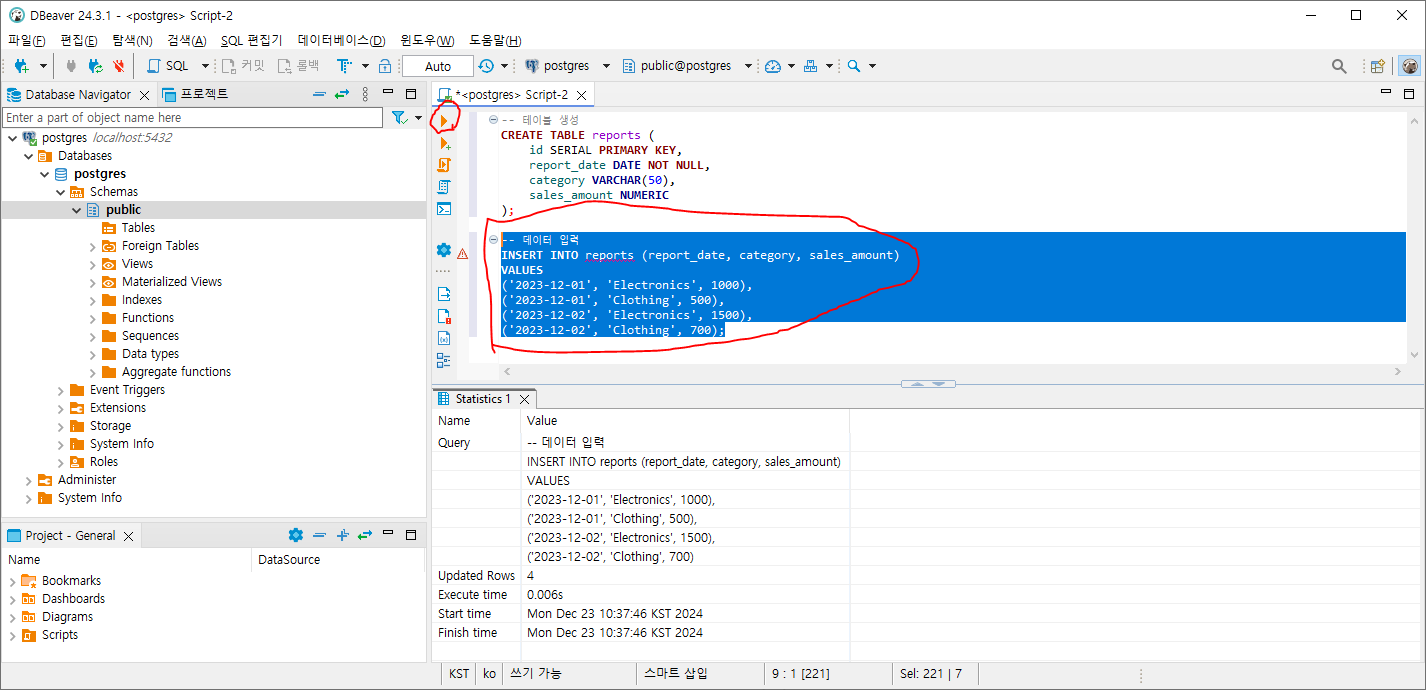
데이터 생성 (아래와 같이 마우스로 쿼리 선택 후, 쿼리의 좌측의 노란색 화살표를 선택하거나, (Ctrl + Enter) 를 입력)
2. 필요한 라이브러리 설치
- VS CODE의 터미널에서 아래의 명령을 실행
pip install streamlit sqlalchemy psycopg2 pandas matplotlib seaborn
sqlalchemy psycopg2 라이브러리 설명
SQLAlchemy
SQLAlchemy는 Python용 SQL 툴킷 및 객체 관계 매핑(ORM) 라이브러리입니다
주요 용도는 다음과 같습니다:- ORM 기능: 데이터베이스 테이블을 Python 클래스로 매핑하여 객체 지향적으로 데이터베이스를 다룰 수 있게 합니다
- SQL 추상화: 다양한 데이터베이스 시스템(MySQL, PostgreSQL, SQLite 등)에 대해 일관된 API를 제공합니다
- 쿼리 생성: Python 코드로 복잡한 SQL 쿼리를 생성할 수 있습니다
- 트랜잭션 관리: 데이터베이스 트랜잭션을 효율적으로 관리할 수 있습니다
psycopg2
psycopg2는 PostgreSQL 데이터베이스를 위한 Python 어댑터입니다
주요 용도는 다음과 같습니다:- PostgreSQL 연결: Python 애플리케이션과 PostgreSQL 데이터베이스 간의 연결을 제공합니다
- SQL 실행: PostgreSQL 데이터베이스에 대해 직접 SQL 쿼리를 실행할 수 있습니다
- 데이터 검색 및 조작: 데이터베이스로부터 데이터를 가져오거나 데이터를 수정할 수 있습니다
- 트랜잭션 관리: PostgreSQL 데이터베이스의 트랜잭션을 관리할 수 있습니다
SQLAlchemy가 더 높은 수준의 추상화를 제공하는 반면, psycopg2는 PostgreSQL에 특화된 더 낮은 수준의 제어를 제공합니다. 많은 경우 SQLAlchemy는 내부적으로 psycopg2를 사용하여 PostgreSQL과 통신합니다
3. 아래의 Streamlit 코드를 app.py 로 생성합니다.
import streamlit as st
import pandas as pd
import sqlalchemy
import seaborn as sns
import matplotlib.pyplot as plt
# 데이터베이스 연결 설정
# username, password, dbname 을 변경해 줍니다.
# DB_URL = "postgresql+psycopg2://username:password@localhost/dbname"
DB_URL = "postgresql+psycopg2://postgres:1111@localhost/postgres"
# 데이터베이스와 연결
engine = sqlalchemy.create_engine(DB_URL)
# 데이터 가져오는 함수
@st.cache_data
def fetch_data():
query = "SELECT * FROM reports ORDER BY report_date"
return pd.read_sql(query, con=engine)
# Streamlit 애플리케이션
st.title("📊 레포트 프로그램")
# 데이터 로드
st.sidebar.header("필터")
data = fetch_data()
# 데이터 필터링
st.sidebar.subheader("날짜 필터")
date_range = st.sidebar.date_input("날짜 범위 선택", [])
if date_range:
data = data[
(data["report_date"] >= pd.to_datetime(date_range[0])) &
(data["report_date"] <= pd.to_datetime(date_range[1]))
]
st.sidebar.subheader("카테고리 필터")
category_filter = st.sidebar.multiselect("카테고리 선택", data["category"].unique(), default=data["category"].unique())
if category_filter:
data = data[data["category"].isin(category_filter)]
# 데이터 미리보기
st.subheader("📋 데이터 미리보기")
st.dataframe(data)
# 요약 레포트
st.subheader("📄 요약 레포트")
if not data.empty:
summary = data.groupby("category")["sales_amount"].sum().reset_index()
st.write(summary)
else:
st.write("선택된 데이터가 없습니다.")
# 그래프 시각화
st.subheader("📈 매출 그래프")
if not data.empty:
fig, ax = plt.subplots(figsize=(10, 5))
sns.barplot(data=data, x="report_date", y="sales_amount", hue="category", ax=ax)
ax.set_title("날짜별 카테고리 매출")
st.pyplot(fig)
else:
st.write("그래프를 표시할 데이터가 없습니다.")
# 다운로드 버튼 추가
st.sidebar.subheader("📥 다운로드")
if not data.empty:
csv = data.to_csv(index=False)
st.sidebar.download_button(label="CSV 다운로드", data=csv, file_name="report.csv", mime="text/csv")
else:
st.sidebar.write("다운로드할 데이터가 없습니다.")
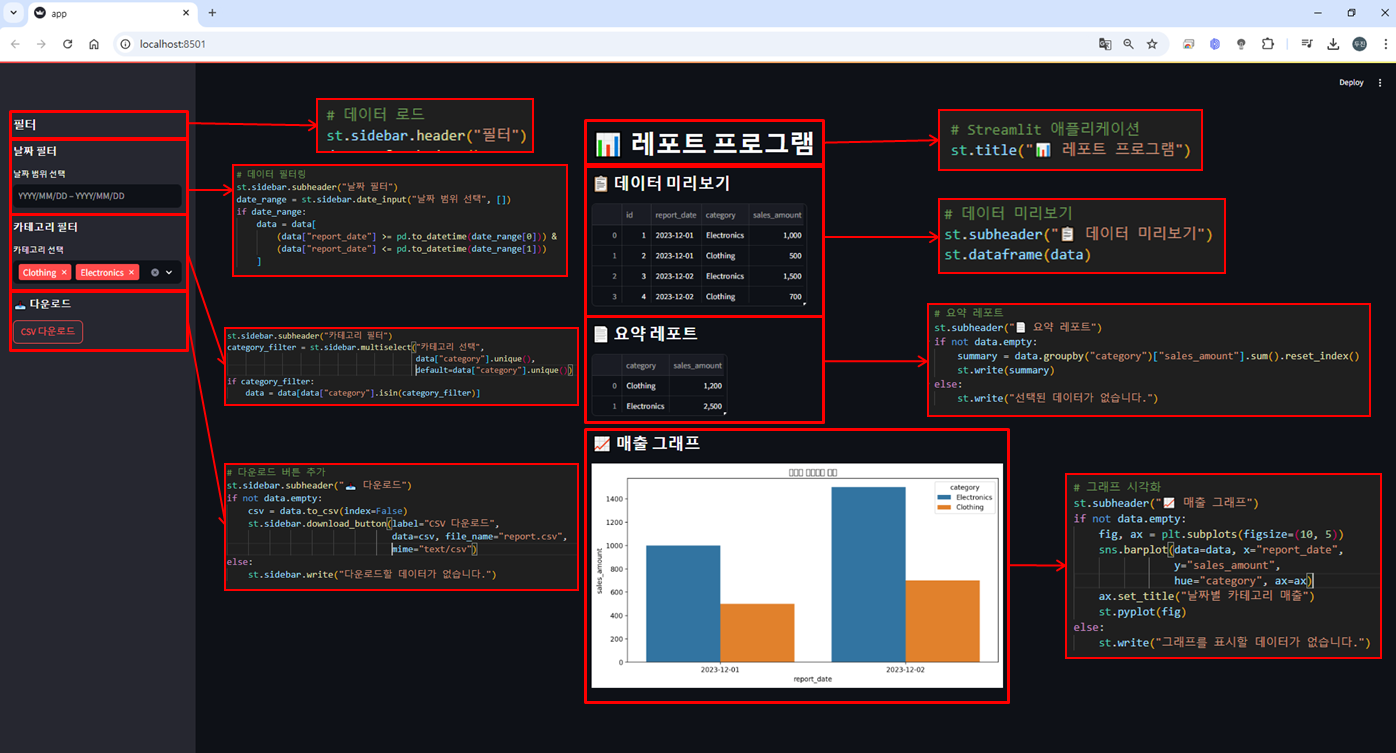
코드 <-> 화면 UI 비교
4. Streamlit app 실행, VS Code의 터미널에서 아래의 명령을 실행하여, app 을 실행합니다.
streamlit run app.py
5. 아래와 같이, 웹 브라우저에서 http://localhost:8501로 자동 접속 됩니다.
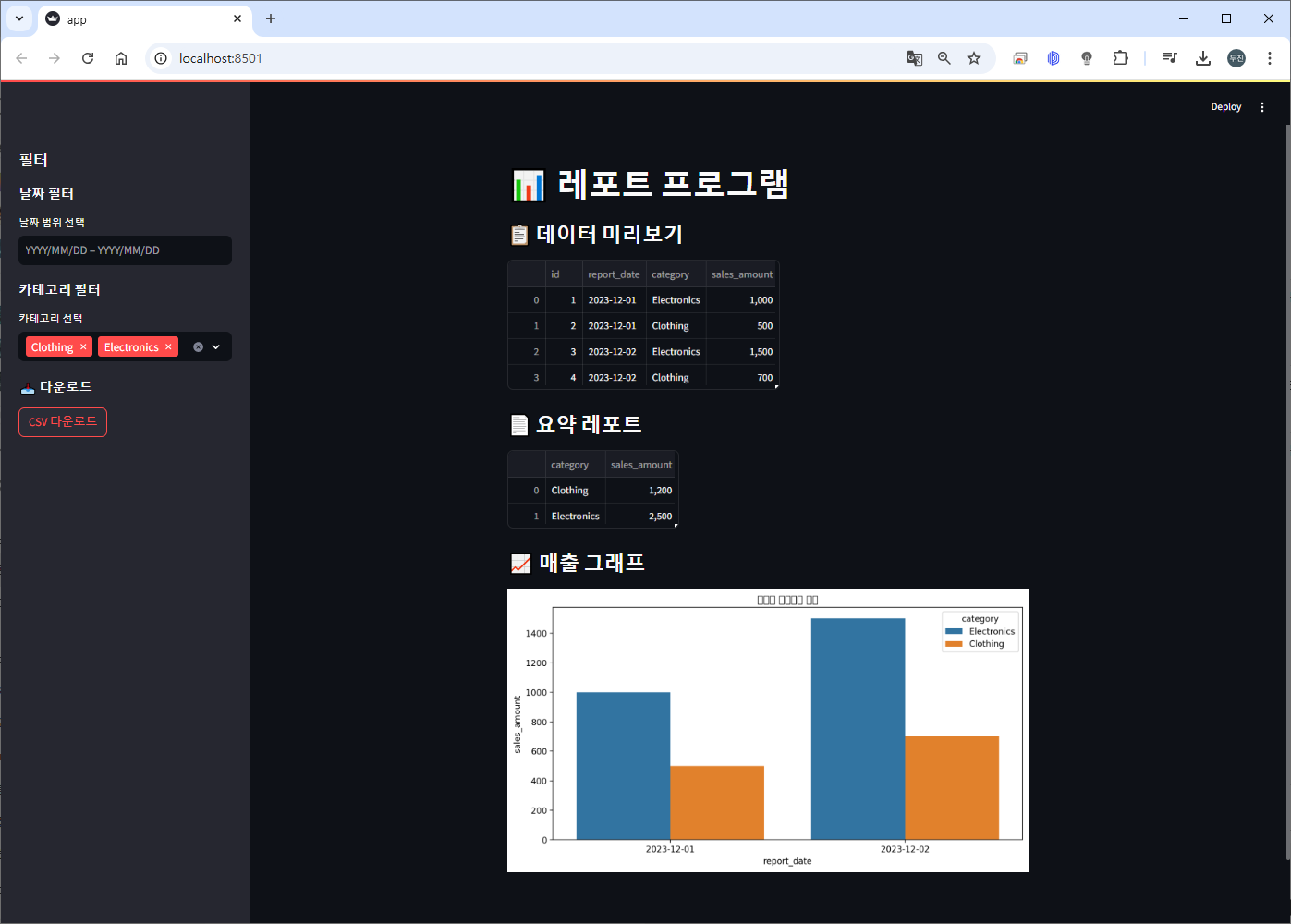
끝~

'AI Tutorial' 카테고리의 다른 글
| [Hugging Face - 2] Transformer? (1) | 2024.12.24 |
|---|---|
| [Hugging Face - 1] Hugging Face 소개 및 기본사용(Feat. pipeline) (0) | 2024.12.23 |
| [Python 모델 서빙] DJango - 써보기(Visual Studio Code에서 Django 튜토리얼-1) (0) | 2024.12.19 |
| [Python 모델 서빙] Flask - 써보기(Visual Studio Code의 Flask 튜토리얼 - 1) (0) | 2024.12.16 |
| [Python 모델 서빙] FastApi - 써보기(기본) (1) | 2024.12.15 |



